MSP430 - Assembler und Code-Optimierung
- Motivation: Entwickeln eines Gefühls, welche C-Befehle wie viel Laufzeit im MSP430 benötigen.
- Dazu muss kenngelernt werden:
- Wie führt der MSP430 Befehle aus?
- Wie sieht der Op-Code aus?
- Wie sehen typische C-Konstrukte im Opcode aus?
Register und Adressbereich des MSP430



Speichereinheiten
- Register des MSP430 sind 1 Wort / 2 Byte / 16 bit groß.
- Aber Speicherzellen sind nur 1 Byte / 8 bit groß.
→ Es werden zwei Speicherzellen benötigt, um ein Register abzulegen. - In welcher Reihenfolge werden MSByte und LSByte im Speicher abgelegt?
- Little Endian vs. Big Endian
- Der MSP430 verwendet die Little Endian Reihenfolge
- LSByte wird an der Adresse abgelegt
- MSByte wird an der Adresse+1 abgelegt
Aufbau des MSP430-Maschinencodes
Übersicht von Matt Laubhan (University of Colorado at Colorado Springs): https://academics.uccs.edu/mlaubhan/MSP430/ece3430/MSP430InstructionSetEncodings.htm
Adressierungsarten
- Konstanten (#0xA5, #8, ...)
- Registeradressierung (R15, R14, PC, SR, SP, ...)
- Absolute Adressierung (&0x200, &0x21, ...)
- Indirekte Adressierung (@R14, nur Quelloperand)
- Indirekte Adressierung mit Postinkrement (@R14+, nur Quelloperand)
- Indizierte Adressierung (0x200(R14), 0(R15))
Rechenbefehle
- Normale Rechenbefehle
- MOV(.B) src, dst:
dst = src; - ADD(.B) src, dst:
dst += src; - ADDC(.B) src, dst:
dst += src + C; - SUB(.B) src, dst:
dst -= src; - SUBC(.B) src, dst:
dst -= src + C; - CMP(.B) src, dst:
dst - src;(nur Flags von Interesse, Ergebnis der Rechnung wird verworfen) - DADD(.B) src, dst: Dezimaladdition
dst += src; - BIT(.B) src, dst:
src & dst;(nur Flags von Interesse, Ergebnis der Rechnung wird verworfen) - BIC(.B) src, dst:
dst &= ~src; - BIS(.B) src, dst:
dst |= src; - XOR(.B) src, dst:
dst ^= src; - AND(.B) src, dst:
dst |= src; - RRA(.B) / RRC(.B) dst:
dst = dst >> 1;, ggf. mit C - SWPB dst: Tauschen der Bytes
- SXT dst: Vorzeichenerweiterung von Byte → Wort
- MOV(.B) src, dst:
- Emulierte Rechenbefehle:
- DEC(.B) dst:
dst--;(SUB(.B) #1, dst) - DECD(.B) dst:
dst -= 2;(SUB(.B) #2, dst) - INC(.B) dst:
dst++;(ADD.x #1, dst) - INCD(.B) dst:
dst += 2;(ADD.x #2, dst) - INV(.B) dst:
dst = ~dst;(XOR.x #−1, dst) - RLA/C(.B) dst:
dst = dst << 1;(ADD(C)(.B) dst, dst)
- DEC(.B) dst:
- Operationen, wie DADD oder SWAP haben keine äquivalente Operationen in C. Aus diesem Grund gibt es in CCS Intrinsic:
Verzweigungen im Assembler
- Nutzen des CMP oder BIT-Befehls...
- ...in Kombination mit Sprung-Befehlen:
- JNE/JNZ Jump if not equal/zero
- JEQ/JZ Jump if equal/zero
- JNC/JLO Jump if no carry/lower
- JC/JHS Jump if carry/higher or same
- JN Jump if negative
- JGE Jump if greater or equal
- JL Jump if less
- JMP Jump (unconditionally)
- Beispiel einer einfachen
if-Anweisung
Beispiel einer Verzweigung in C und Assembler
Schleifen in Assembler
- Programmierung von Schleifen analog zu Verzweigungen: Nutzen von Sprungbefehlen
- Vergleich: Aufzählen oder Abzählen in einer Schleife:
Beispiel einer aufzählenden Schleife von C und ASM
CLR.B &0x21
CMP.B #0xAB,&0x21
JHS ($C$L4)
$C$L3:
INC.B &0x21
CMP.B #0xAB,&0x21
JLO ($C$L3)
$C$L4:
...
Beispiel einer abzählenden Schleife von C und ASM
Stapeloperationen
- Stapel (engl. stack)
- Mögliche Stapelzugriffe:
- Ein Blatt von oben auf den Stapel legen. (PUSH)
- Ein Blatt vom Stapel nehmen und lesen. (POP)
- Der Stapel des MSP430 wird am Ende des RAM-Bereiches aufgebaut.
- Der Stapel wird von hohen Adressen zu niedrigeren Adressen gefüllt.
- Der Stapelzeiger zeigt auf das obereste Stapelwort.
- PUSH: Wert des Stapelzeigers wird verringert.
- POP: Wert des Stapelzeigers wird erhöht.
Funktionsaufruf
- Eine Prozedur ist im Assembler eine Folge von Maschinenbefehlen, die einmalig definiert wird und an beliebigen Stellen im Programm aufgerufen werden kann.
- Da der Aufruf an verschiedenen Stellen erfolgen kann, können keine einfachen Sprungbefehle verwendet werden, um die Prozedur aufzurufen.
- Lösung: CALL- und RET-Befehl
Funktionsaufruf und Funktionsrumpf in C und Assembler
Funktionsaufruf und Funktionsrumpf mit einem Parameter in C und Assembler
- Für die ersten beiden Parameter werden die Register R14 und R12 verwendet.
- Weitere Parameter werden auf dem Stack abgelegt.
- Das Ergebnis einer Function wird in R12 abgelegt.
Quelle: Texas Instruments, Mixing C and Assembler With the MSP430 (SLAA140) - Im Stack einer CPU kann nachvollzogen, welche Funktionen baumartig aufgerufen wurden:
- z. B. kann im Fehlerfall der stack trace ausgegeben werden.
- Treten zu viele Funktionsaufrufe in einander auf (z. B. bei einem rekursiven Programm) kommt es zu einen stack overflow
- z. B. kann im Fehlerfall der stack trace ausgegeben werden.
Interrupts
- Tritt ein Interrupt auf dem MSP430 ein, so wird der aktuelle Befehl ausgeführt.
- Das Statusregister und der PC wird auf den Stapel gelegt. (PUSH PC, PUSH SR)
- Aus dem Interruptvektor wird die Startadresse der passenden ISR ausgelesen.
- Die ISR wird ausgeführt.
- Eine ISR endet mit einem RETI-Befehl. Dieser hat die Wirkung von (POP SR, POP PC)
- Das Hauptprogramm arbeitet weiter.
Interrupt-Service-Routine in C und Assembler
#pragma vector=PORT2_VECTOR
__interrupt void PORT2_ISR() {
if (P2IFG & BIT0) {
P2IFG &= ~BIT0;
__low_power_mode_off_on_exit();
}
}
Low-Power-Modi
- Der LPM wird über die Bits SCG1/0 und OSCOFF/CPUOFF des Statusregisters bestimmt.

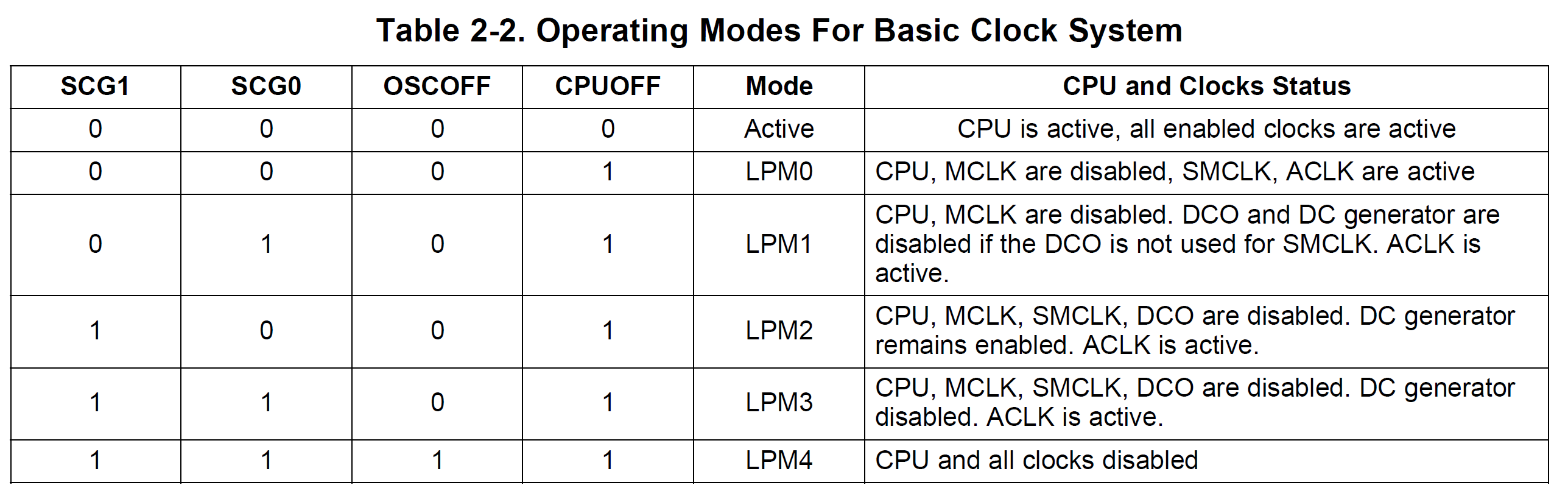
- Betreten des Low-Power-Modus durch Setzen der Bits im SR
- Verlassen des LPM im Interrupt: Statusregister steht an oberster Stelle im Stapel
Optimierungsmöglichkeiten
Automatische Optimierungsmöglichkeiten
- Der C-Compiler für den MSP430 besitzt die Möglichkeit selbstständig den Code zu optimieren.
- Siehe Project Properties/MSP430 Compiler/Optimization
- Verschiedene Stufen der Optimierung:
- off
- 0: Register Optimizations
- 1: Local Optimizations
- 2: Global Optimizations
- 3: Interprocedure Optimizations
- 4: Whole Program Optimizations
- Einstellung: Speed vs. size trade off
Beispiel: Lookup-Table: Viel Speicher, aber extrem schnell - Problem: Je höher das Optimierungslevel, desto schlechter kann das Programm mit dem Live-Debugger untersucht werden (Funktionen und Variablen werden verändert)
Konstanten
Beispiel zu Konstanten und der #define-Anweisung
uint8_t keine_konstante = 0x77;
const uint8_t konstante = 0x55;
#define KONSTANTE 0x33
int main(void) {
...
P1OUT = keine_konstante;
P1OUT = konstante;
P1OUT = KONSTANTE;
}
Disassembly des Beispiel oberhalb
96 P1OUT = keine_konstante;
80d8: 42D2 0200 0021 MOV.B &keine_konstante,&Port_1_2_P1OUT
97 P1OUT = konstante;
80de: 40F2 0055 0021 MOV.B #0x0055,&Port_1_2_P1OUT
98 P1OUT = KONSTANTE;
80e4: 40F2 0033 0021 MOV.B #0x0033,&Port_1_2_P1OUT
- Wird eine Konstante nicht mit dem Schlüsselwort
staticversehen wird diese im RAM abgespeichert. (Die Variablekeine_konstantehat die Adresse 0x200.) - Konstanten mit
constoder#definewerden gleich behandelt → die Konstante wird in diesen Fall direkt in die Anweisung eingetragen. - Unterschied zwischen
#defineundconst#define-Anweisungen werden in die Header-Datei geschrieben und sind für alle Module zugänglich.#define-Anweisungen werden vorm Compilieren ausgewertet → vom Compiler können so Konstanten berechnet werden.const-Konstanten haben einen festen Datentyp und sind daher sicherer als#define-Konstantenconsts kännen mit dem Schlüsselwortstaticversehen werden und als lokale Konstanten benutzt werden.- Um die Werte von
#define-Konstanten sollte immer eine Klammer gesetzt werden. Beispiel:
Beispiel einer fehlerhaften #define-Anweisung
Praxis-Beispiele
- Registermap eines Sensors: https://github.com/jhester/msp430-cc1101/blob/master/registers.h
- Enums können auch sehr gut zur Konstantedefinition verwendet werden.
Enum als Flags
typedef enum {
ISR_WDT = (1 << 0),
ISR_I2C_UPDATE = (1 << 1),
ISR_BUTTON_PRESSED = (1 << 2),
ISR_BATTERY_READY = (1 << 3),
ISR_ALARM_BATTERY_LEVEL = (1 << 5),
ISR_ALARM_WATCHDOG = (1 << 6),
ISR_BUTTON2_PRESSED = (1 << 7)
} isr_flags_t;
- Werden Enums automatisch nummeriert, so kann ein Element am Ende die Anzahl der Glieder angeben:
Automatisch nummeriertes Enum mit Längenangabe
typedef enum {
ALARM_BATTERY_LEVEL = 0,
ALARM_WATCHDOG,
ALARM_KEY_PRESSED,
ALARM_BATTERY,
ALARM_LENGTH
} alarms_t;
- Es gibt insgesamt vier Alarme →
ALARM_LENTHbekommt automatisch den Wert 4 zugewiesen.ALARM_LENGTHkann z. B. als obere Grenze in einerfor-Schleife verwendet werden.
Geschwindigkeitsmessung
Geschwindigkeitsmessung mit Timer A
void tick() {
TACTL = TASSEL_2 + MC_2 + TACLR;
}
uint16_t tock() {
TACTL = 0;
return TAR - 12;
}
int main(void) {
...
tick();
t1 = tock(); // liefert 0
}
Funktionsaufrufe
- Funktionsaufrufe benötigen mehr CPU-Laufzeit auf Grund der CALL- und RET-Anweisung.
- Mit Hilfe von Makros können kleine Funktionsteile direkt im Code eingefügt werden.
Unterschied zwischen einer normalen Funktion und einem Makro
void func_normal() {
P1OUT |= BIT0;
}
#define MACRO() (P1OUT |= BIT0)
int main(void) {
...
tick();
func_normal();
t2 = tock(); // 12
tick();
MACRO();
t3 = tock(); // 4
}
- In diesem Fall benötigt der normale Funktionsaufruf mehr Zeit und Speicherplatz.
- Der Compiler führt eine Optimierung erst ab 3-Interprocedure Optimizations durch.
Alternative: Inline-Funktionen
- Mit den Schlüsselwort inline kann der Compiler hingewiesen werden, den Funktionsaufruf zu unterbinden.
Beispiel einer Inline-Funktion
- Inline-Funktionen besitzen keine Prototypen. Globale Inline-Funktionen müssen im Header definiert werden.
Praxis-Beispiel: Funktionen für die Pin-Konfiguration
Beispiel einer Header-Datei mit Funktionen für die Pin-Konfiguration
#ifndef PINS_H_
#define PINS_H_
#define P_CLOCK_FREQ_MHZ 1
// PORT 1
#define P_LED BIT0
#define P_SPIA_MISO BIT1
#define P_SPIA_MOSI BIT2
#define P_SPIRIT_CS BIT3
#define P_SPIA_SCK BIT4
#define P_UART_RXD P_SPIA_MISO
#define P_UART_TXD P_SPIA_MOSI
#define P_PORT1_UNUSED (BIT5 + BIT6 + BIT7)
// PORT2
#define P_SPIRIT_IRQ BIT0
#define P_XIN BIT6
#define P_XOUT BIT7
#define P_PORT2_UNUSED (BIT1 + BIT2 + BIT3 + BIT4 + BIT5)
// SPIA @ P1.1, P1.2, P1.4
#ifndef P_SPIA_DISABLE
inline void p_spia_setup() {
P1SEL |= P_SPIA_MISO + P_SPIA_MOSI + P_SPIA_SCK;
P1SEL2 |= P_SPIA_MISO + P_SPIA_MOSI + P_SPIA_SCK;
P1DIR |= P_SPIA_MOSI + P_SPIA_SCK;
}
#endif
// LED @ P1.0 - OUT
#ifndef P_LED_DISABLE
inline void p_led_setup() {
P1OUT &= ~P_LED;
P1DIR |= P_LED;
}
inline void p_led_h() {
P1OUT |= P_LED;
}
inline void p_led_l() {
P1OUT &= ~P_LED;
}
inline void p_led_toggle() {
P1OUT ^= P_LED;
}
#endif
...
// SPIRIT_IRQ @ P2.0 - interrupt falling edge
#ifndef P_SPIRIT_IRQ_DISABLE
inline void p_spirit_irq_setup() {
P2DIR &= ~P_SPIRIT_IRQ;
P2IES |= P_SPIRIT_IRQ;
P2IFG &= ~P_SPIRIT_IRQ;
P2IE |= P_SPIRIT_IRQ;
}
inline uint8_t p_spirit_irq_ifg() {
return P2IFG & P_SPIRIT_IRQ;
}
inline void p_spirit_irq_ifg_clr() {
P2IFG &= ~P_SPIRIT_IRQ;
}
#endif
// SETUP
inline void pins_setup() {
#if P_CLOCK_FREQ_MHZ == 1
BCSCTL1 = CALBC1_1MHZ;
DCOCTL = CALDCO_1MHZ;
#elif P_CLOCK_FREQ_MHZ == 8
BCSCTL1 = CALBC1_8MHZ;
DCOCTL = CALDCO_8MHZ;
#elif P_CLOCK_FREQ_MHZ == 12
BCSCTL1 = CALBC1_12MHZ;
DCOCTL = CALDCO_12MHZ;
#elif P_CLOCK_FREQ_MHZ == 16
BCSCTL1 = CALBC1_16MHZ;
DCOCTL = CALDCO_16MHZ;
#endif
// PORT1
p_led_setup();
p_spirit_cs_setup();
p_spia_setup();
// PORT2
p_spirit_irq_setup();
// Unused Pins
P1OUT &= ~P_PORT1_UNUSED;
P1REN |= P_PORT1_UNUSED;
P2OUT &= ~P_PORT2_UNUSED;
P2REN |= P_PORT2_UNUSED;
}
#define p_delay_ms(t) (__delay_cycles(P_CLOCK_FREQ_MHZ * 1000L * (t)))
#define p_delay_us(t) (__delay_cycles(P_CLOCK_FREQ_MHZ * (t)))
- Einfache Möglichkeit Pins zu tauschen, nachdem das gesamten Programm geschrieben wurde.
- Keine Performance-Verluste durch inline-Funktionen.
SPI-Schnittstelle
- Wird sehr häufig für den Transport von großen Datenmengen verwendet.
- z. B. SPI-Slaves: Funkchips, Speicherchips (RAM, Flash, FRAM), SD-Karte
- Große Datenmengen machen Timing von großer Bedeutung.
- Theoretisch maximal erreichbare Datenrate = Frequenz der MCLK
z. B. MCLK = 1 MHz → Datenrate = 1 Mbit/s = 125 kByte/s - Beispiel: Senden von Daten mit der Funktion
spi_send(uint8_t *data, uint8_t len)
Optimierung einer SPI-Übertragung - Variante 1
void spi_send(const uint8_t *data, uint8_t len) {
while (UCB0STAT & UCBUSY) {
}
for (uint8_t i = 0; i < len; i++) {
UCB0TXBUF = data[i];
while (UCB0STAT & UCBUSY) {
}
}
}
- Laufzeit der Variante 1: 260 µs → 38,4 kByte/s
Optimierung einer SPI-Übertragung - Variante 2
void spi_send(const uint8_t *data, uint8_t len) {
while (UCB0STAT & UCBUSY) {
}
while (len > 0) {
UCB0TXBUF = *data;
data++;
len--;
while (UCB0STAT & UCBUSY) {
}
}
}
- Laufzeit der Variante 2: 205 µs → 48,7 kByte/s
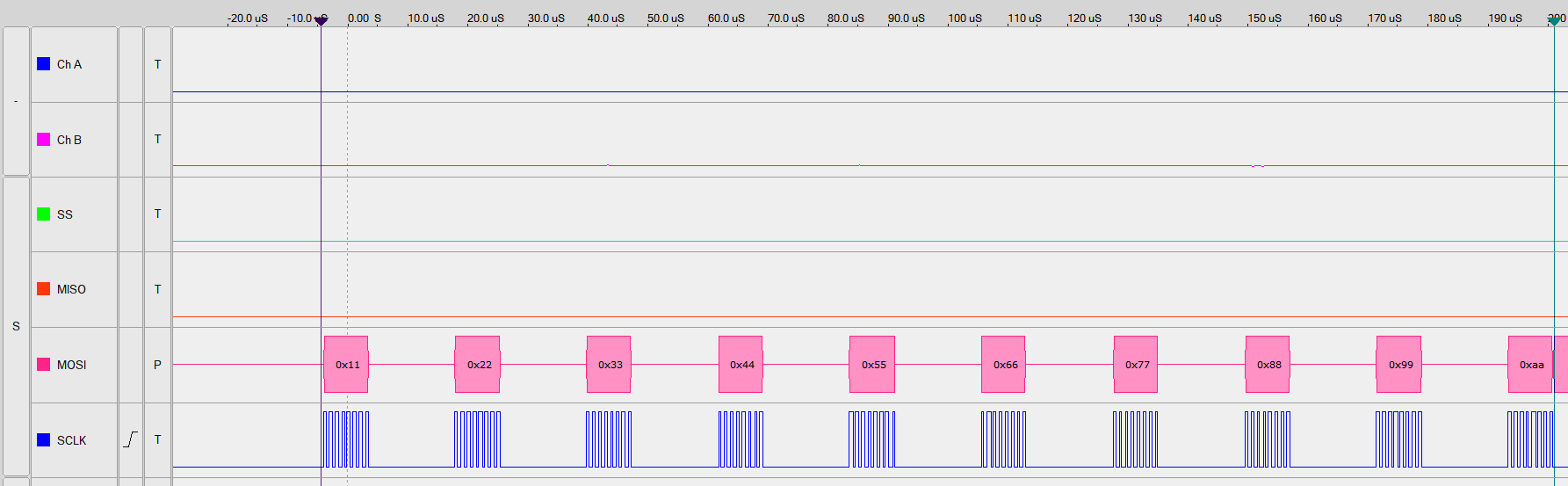
Optimierung einer SPI-Übertragung - Variante 3
void spi_send(const uint8_t *data, uint8_t len) {
while (len > 0) {
while (UCB0STAT & UCBUSY) {
}
UCB0TXBUF = *data;
data++;
len--;
}
}
- Laufzeit der Variante 3: 198 µs → 50,5 kByte/s
Optimierung einer SPI-Übertragung - Variante 4
void spi_send(const uint8_t *data, uint8_t len) {
while (len > 0) {
while (!(IFG2 & UCA0TXIFG)) {
}
UCB0TXBUF = *data;
data++;
len--;
}
}
- Laufzeit der Variante 4: 142 µs → 70,4 kByte/s
Optimierung einer SPI-Übertragung - Variante 5
void spi_send(const uint8_t *data, uint8_t len) {
while (len > 0) {
UCB0TXBUF = *data;
data++;
len--;
}
}
- Laufzeit der Variante 5: 88 µs → 113,6 kByte/s
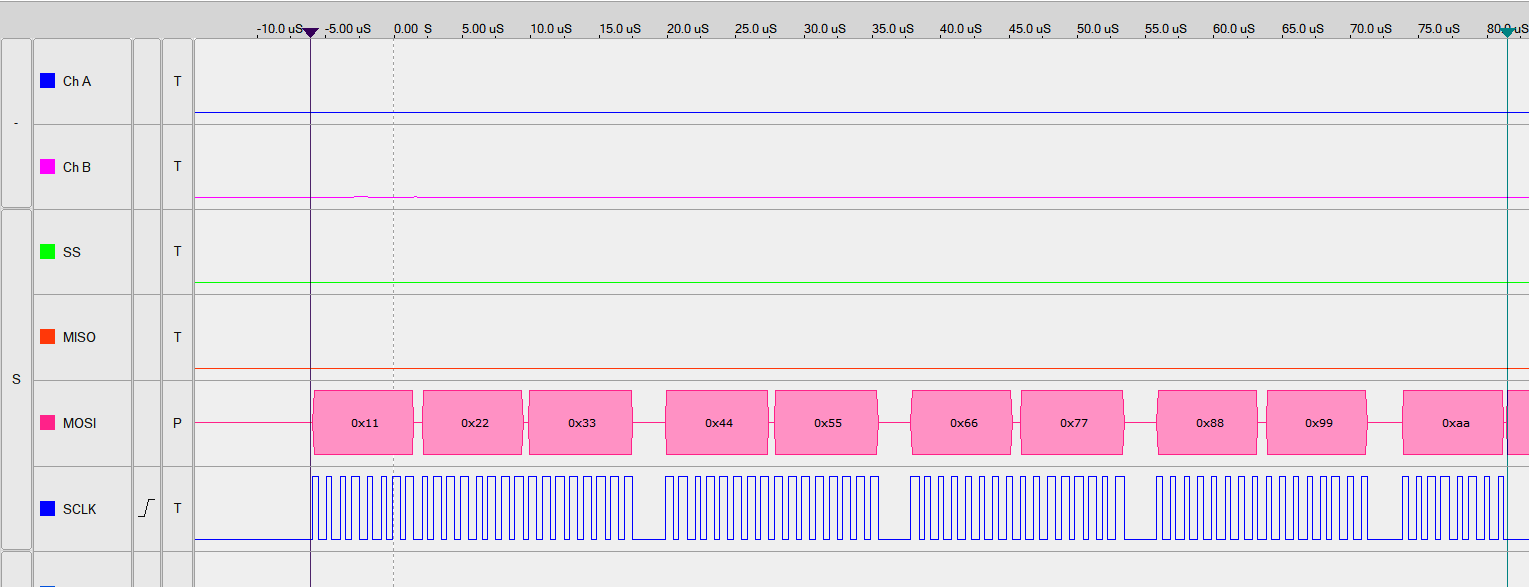
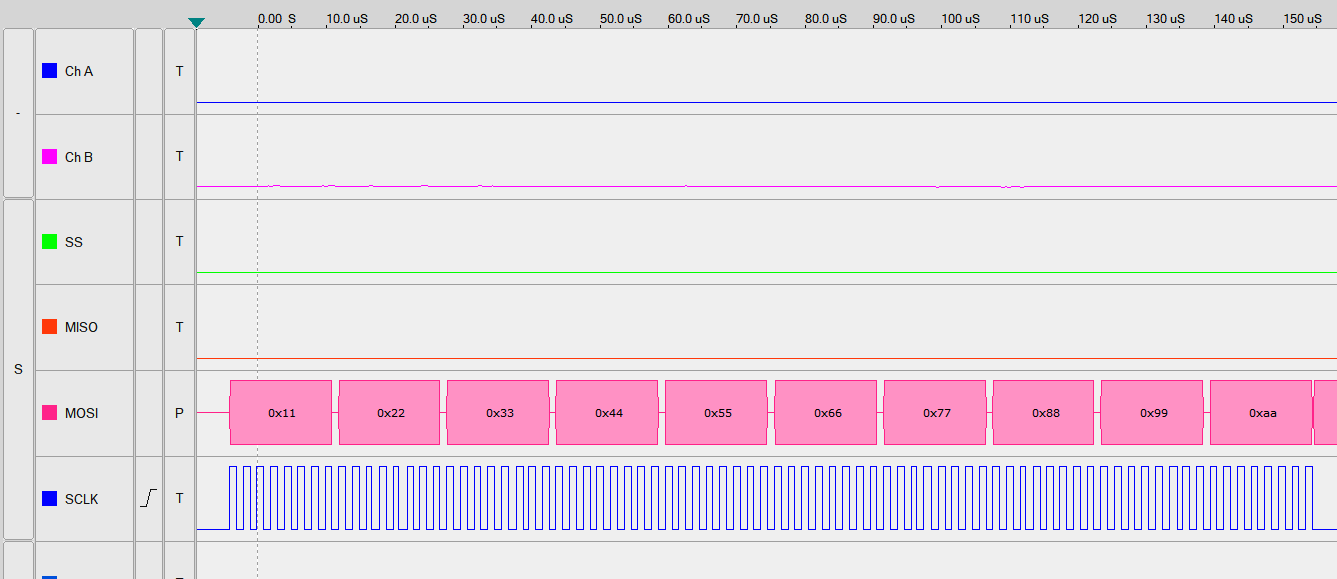
- Analyse des Verhalten der Funktion - Warum funktioniert die Funktion ohne Flag-Polling?
spi_send():
TST.B R13
JEQ ($C$L2)
$C$L1:
MOV.B @R12,&UCB0TXBUF
INC.W R12
DEC.B R13
JNE ($C$L1)
$C$L2:
RET
| Befehl | Beschreibung | Anzahl der CPU-Zyklen |
|---|---|---|
MOV.B @R12,&UCB0TXBUF |
MOV, Indirekte Adressierung, Adressadressierung | 5 |
INC.W R12 |
ADD #1, R12: Registeradressierung, Konstantengenerator | 1 |
DEC.B R13 |
SUB #1, R13: Registeradressierung, Konstantengenerator | 1 |
JNE ($C$L1) |
Bedingter Sprungbefehl | 2 |
| siehe Family Guide S. 60ff |
→ 9 CPU-Zyklen pro SPI-Byte → Es entsteht eine Pause von 2 µs alle 2 Bytes.
- Das Ganze funktioniert nur bei einen SPI-Taktteiler von 1 (
UCB0BR0 = 1;) - Was passiert bei
UCB0BR0 = 2;?
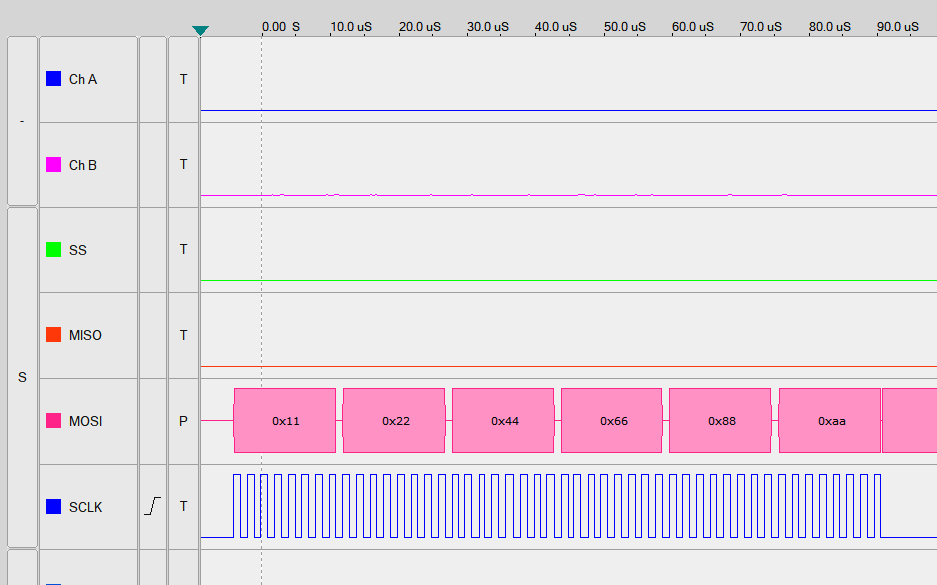
Angepasste Programmierung bei geteilter SPI-Taktfrequenz
void spi_send(const uint8_t *data, uint8_t len) {
while (len > 0) {
UCB0TXBUF = *data;
__delay_cycles(7);
data++;
len--;
}
}
- 16 Taktzyklen werden von der SPI-Schnittstelle pro Byte benötigt, 9 Taktzyklen benötigt das Programm → Verzögerung um 7 Zyklen
__delay_cycles()verzögert das Programm um exakt die angegebenen Taktzyklen z. B. (NO-OP-Instruction)
__delay_cycles(7) Anweisung im Disassembly
Verwendung von Structs
Übergabe von Structs
- Mit Hilfe von Structs können komplexe Datenstrukturen in C dargestellt werden.
- Achtung! Stucts können sehr schnell groß werden und sollten daher wenn möglich nicht kopiert werden.
- Die Übergabe eines Structs erfolgt im Assemblercode immer als Zeiger
- Soll das Struct in der Funktion modifiziert werden, muss es als Zeiger übergeben werden.
Übergabe des Structs als Wert und als Zeiger
void struct_func1(example_t example) { ... }
void struct_func2(const example_t *example) { ... }
...
struct_func1(example);
struct_func2(&example);
63 struct_func1(example);
80d4: 410C MOV.W #0x8234,R12
80d6: 12B0 820C CALL #struct_func1
64 struct_func2(&example);
80da: 403C 8234 MOV.W #0x8234,R12
80de: 12B0 8228 CALL #struct_func2
Anordnung der Daten von Structs
- Die Daten eine Structs werden hintereinander angeordnet.
- Die Reihenfolge wird in der Regel eingehalten.
- Es findet sogenanntes "Padding" statt. D. h. ein uint16_t darf nicht mit einer ungeraden Adresse beginnen. → Es muss ein leeres Byte eingefügt werden!
- Am Beispiel:
Beispiel-Struct zur Veranschaulichung der Anordnung der Daten
typedef enum {
GENDER_MALE = 1, GENDER_FEMALE = 2
} gender_t;
typedef struct {
uint8_t age;
gender_t gender;
uint16_t size_mm;
char name[8];
uint32_t day_of_birth;
} person_t;
const person_t my_person = { .age = 23, .gender = GENDER_MALE, .size = 0x2233,
.name = "Robert", .day_of_birth = 0xaabbccdd };
Beispiel-Struct im Memory Browser
- Nach dem Feld
agemuss ein leeres Byte eingefügt werden. - Das Feld
genderist ein Enum und nimmt standardmäßig 16 Bit ein. - Die kann durch die Einstellung umgestellt werden: Project Properties → Build → MSP430 Compiler → Advanced Options → Runtime Model Options → Designate enum type → packed
Beispiel-Struct im Memory Browser mit 1 Byte Enums
Zugriff auf Struct-Felder
- Der Zugriff auf Struct-Felder durch den MSP430 erfolgt wie bei herkömmlichen Variablen, wenn der Speicherplatz statisch festgelegt wurde.
Zugriff auf ein Feld eines statischen Structs
Versenden und Empfangen von Structs über Kommunikationskanäle
- Zum Versenden muss ein Struct umgewandelt werden in eine Folge von Bytes (Char-Array).
- Dies erfolgt in C mit einen sogennanten Type-Cast:
Beispiel: Versenden eines Structs über SPI
- Entsprechend können die Daten beim Empfänger wieder in ein Struct umgewandelt werden. Hierfür kann ebenfalls ein Type-Cast verwendet werden.
- Es können sogar auf einzelne Bytes des Structs zugriffen werden:
((uint8_t*) &my_person)[index] - Praxis-Beispiel: Aufbau einer Register-Map eines SPI- oder I²C-Slaves: